Quando IAs de conversação como ChatGPT, Perplexity ou Google AI Mode geram trechos ou resumos de respostas, eles não estão escrevendo do zero, mas sim selecionando, compactando e remontando o que as páginas da web oferecem. Se o seu conteúdo não for compatível com SEO e indexável, ele não será incluído na pesquisa generativa. A pesquisa, tal como a conhecemos, é agora uma função da inteligência artificial.
Mas e se a sua página não se “oferecer” em um formato legível por máquina? É aí que entram os dados estruturados, não apenas como um trabalho de SEO, mas como uma estrutura para a IA escolher com segurança os “fatos certos”. Tem havido alguma confusão em nossa comunidade e, neste artigo, irei:
Muitos me perguntaram nos últimos meses se os LLMs usam dados estruturados, e tenho repetido continuamente que um LLM não usa dados estruturados porque não tem acesso direto à rede mundial de computadores. Um LLM usa ferramentas para pesquisar na web e buscar páginas da web. Suas ferramentas – na maioria dos casos – se beneficiam muito da indexação de dados estruturados.
 Imagem do autor, outubro de 2025
Imagem do autor, outubro de 2025Em nossos primeiros resultados, os dados estruturados aumentam a consistência do snippet e melhoram a relevância contextual no GPT-5. Também sugere estender a eficácia palavralim envelope – esta é uma diretiva GPT-5 oculta que decide quantas palavras seu conteúdo receberá em uma resposta. Imagine isso como uma cota de visibilidade de IA que é expandida quando o conteúdo é mais rico e melhor digitado. Você pode ler mais sobre esse conceito, que eu primeiro descrito no LinkedIn.
Minha tese pessoal é que queremos tratar os dados estruturados como uma camada de instrução para IA. Não “classificação para você,” estabiliza o que a IA pode dizer sobre você.
Embora o tamanho da amostra fosse pequeno, eu queria ver como a camada de recuperação do ChatGPT realmente funciona quando usada em sua própria interface, não por meio da API. Para fazer isso, pedi ao GPT-5 para pesquisar e abrir um lote de URLs de diferentes tipos de sites e retornar as respostas brutas.
Você pode solicitar ao GPT-5 (ou qualquer sistema de IA) que mostre a saída literal de suas ferramentas internas usando um meta-prompt simples. Depois de coletar as respostas de pesquisa e busca para cada URL, executei um Fluxo de trabalho do agente WordLift (isenção de responsabilidade, nosso agente AI SEO) para analisar cada página, verificando se incluíam dados estruturados e, em caso afirmativo, identificando os tipos de esquema específicos detectados.
Essas duas etapas produziram um conjunto de dados de 97 URLs, anotados com campos-chave:
Usando uma abordagem “LLM como juiz” desenvolvida pelo Gemini 2.5 Pro, analisei o conjunto de dados para extrair três métricas principais:
Ao executar esses testes, percebi outro padrão sutil, que pode explicar por que os dados estruturados levam a snippets mais consistentes e completos. Dentro do pipeline de recuperação do GPT-5, há uma diretiva interna informalmente conhecida como wordlim: uma cota dinâmica que determina quanto texto de uma única página da web pode transformar-se em uma resposta gerada.
À primeira vista, funciona como um limite de palavras, mas é adaptativo. Quanto mais rico e melhor digitado o conteúdo de uma página, mais espaço ela ganha na janela de síntese do modelo.
Das minhas observações contínuas:
Isso não é arbitrário. O limite ajuda os sistemas de IA:
No entanto, também introduz uma nova fronteira de SEO: seus dados estruturados aumentam efetivamente sua cota de visibilidade. Se seus dados não estiverem estruturados, você terá um limite mínimo; se for, você concede à IA mais confiança e mais espaço para apresentar sua marca.
Embora o conjunto de dados ainda não seja suficientemente grande para ser estatisticamente significativo em todas as verticais, os padrões iniciais já são claros – e acionáveis.
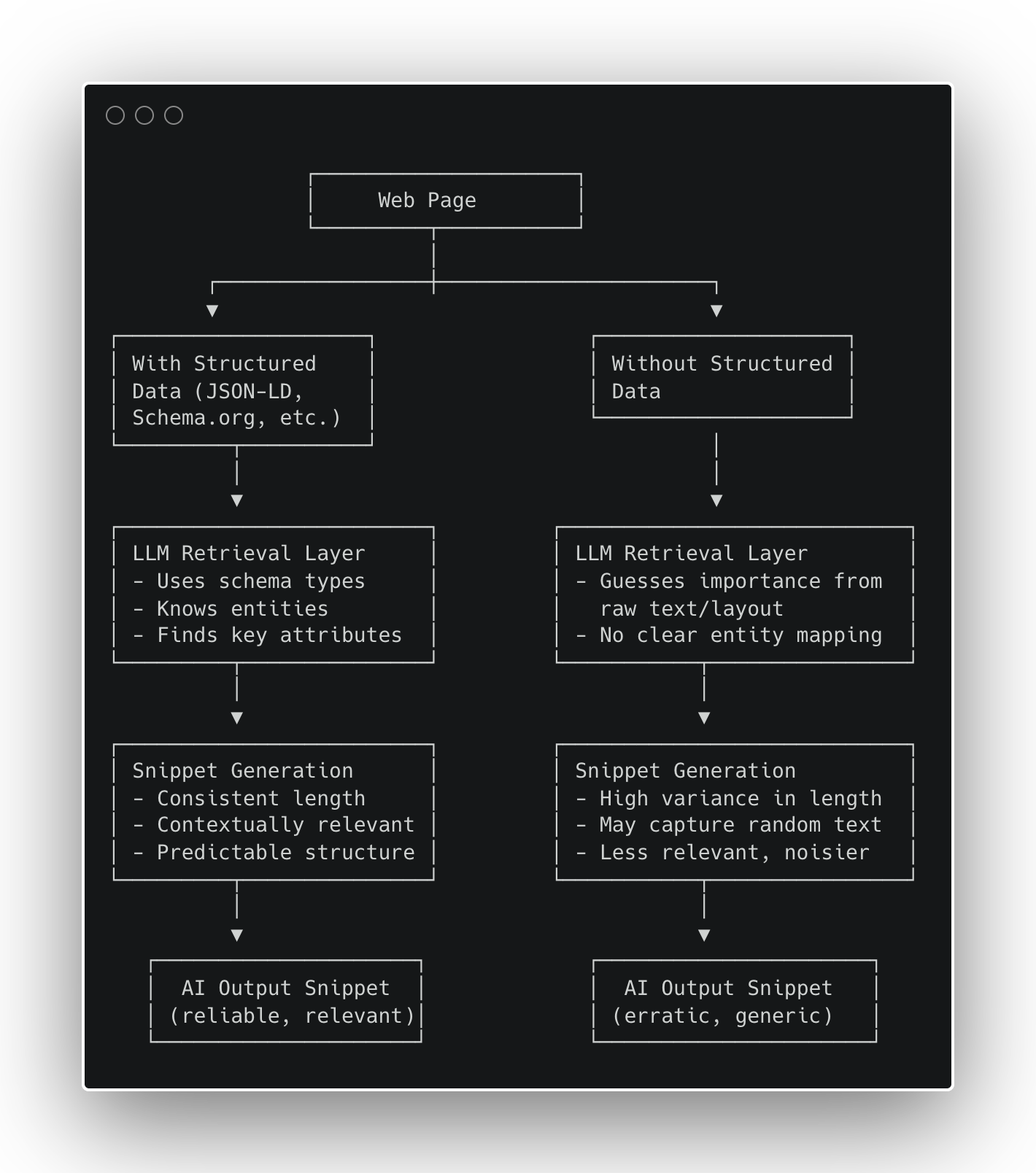 Figura 1 – Como os dados estruturados afetam a geração de snippets de IA (imagem do autor, outubro de 2025)
Figura 1 – Como os dados estruturados afetam a geração de snippets de IA (imagem do autor, outubro de 2025)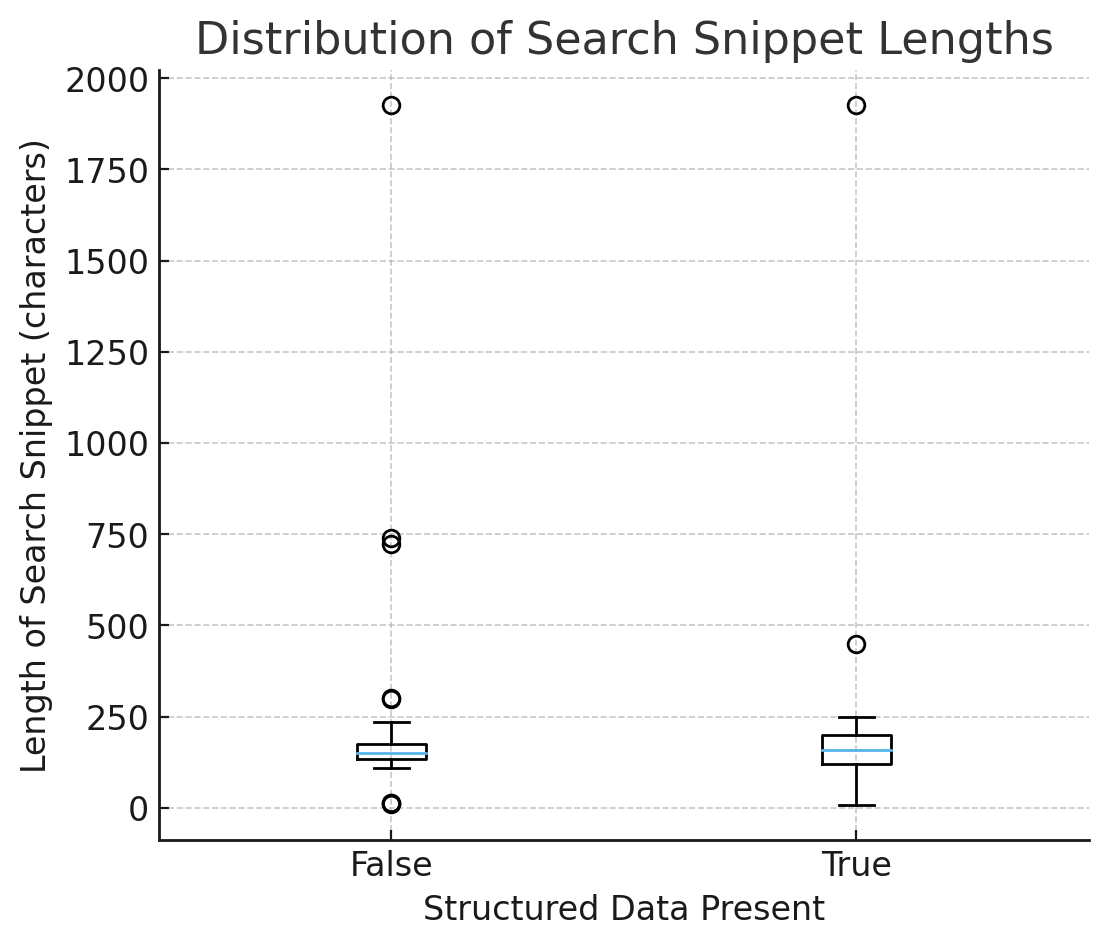 Figura 2 – Distribuição dos comprimentos dos snippets de pesquisa (imagem do autor, outubro de 2025)
Figura 2 – Distribuição dos comprimentos dos snippets de pesquisa (imagem do autor, outubro de 2025)No box plot dos comprimentos dos snippets de pesquisa (com e sem dados estruturados):
Interpretação: Os dados estruturados não aumentam o comprimento; reduz a incerteza. Os modelos são padronizados para fatos seguros e digitados, em vez de adivinhar a partir de HTML arbitrário.
Média da pontuação de 0–1 em todas as páginas:
Mesmo onde as médias parecem semelhantes, a variância entra em colapso com o esquema. Em um mundo de IA limitado por palavralim e sobrecarga de recuperação, a baixa variação é uma vantagem competitiva.
Embora o conjunto de dados ainda não seja grande o suficiente para testes de significância, observamos este padrão emergente:
Páginas com dados estruturados de múltiplas entidades mais ricos tendem a produzir snippets um pouco mais longos e mais densos antes do truncamento.
Hipótese: fatos digitados e interligados (por exemplo, Produto + Oferta + Marca + AggregateRating ou Artigo + autor + data de publicação) ajudam os modelos a priorizar e compactar informações de maior valor – ampliando efetivamente o orçamento de tokens utilizáveis para aquela página.
As páginas sem esquema são frequentemente truncadas prematuramente, provavelmente devido à incerteza sobre a relevância.
Próxima etapa: mediremos a relação entre a riqueza semântica (contagem de entidades/atributos distintos do Schema.org) e o comprimento efetivo do snippet. Se confirmados, os dados estruturados não apenas estabilizam os snippets, mas também aumentam o rendimento informativo sob limites constantes de palavras.
Estruturamos sites como:
Por que funciona: A camada de entidade fornece à IA uma estrutura segura; a camada lexical fornece evidências reutilizáveis e citáveis. Juntos, eles impulsionam a precisão sob opalavralim restrições.
Veja como estamos traduzindo essas descobertas em um manual de SEO repetível para marcas que trabalham sob restrições de descoberta de IA.
Os dados estruturados não alteram o tamanho médio dos fragmentos de IA; isso muda a sua certeza. Ele estabiliza os resumos e molda o que eles incluem. No GPT-5, especialmente sob condições agressivas palavralim condições, essa confiabilidade se traduz em respostas de maior qualidade, menos alucinações e maior visibilidade da marca nos resultados gerados pela IA.
Para SEOs e equipes de produto, a conclusão é clara: trate os dados estruturados como uma infraestrutura central. Se seus modelos ainda não possuem uma semântica HTML sólida, não pule direto para JSON-LD: conserte as fundações primeiro. Comece limpando sua marcação e, em seguida, coloque dados estruturados em camadas para criar precisão semântica e capacidade de descoberta de longo prazo. Na pesquisa de IA, a semântica é a nova área de superfície.
Mais recursos:
Imagem em destaque: TierneyMJ/Shutterstock