O primeiro modelo Gemma lançado no início do ano passado e desde então se tornou um próspero Verso de gema de mais de 160 milhões de downloads coletivos. Esse ecossistema inclui nossa família de mais de uma dúzia de modelos especializados para tudo, desde proteção até aplicações médicas e, o que é mais inspirador, as inúmeras inovações da comunidade. De inovadores como Robofluxo construindo visão computacional empresarial para o Instituto de Ciência de Tóquio criando variantes Gemma japonesas altamente capazes, seu trabalho nos mostrou o caminho a seguir.
Aproveitando esse impulso incrível, temos o prazer de anunciar o lançamento completo do Gemma 3n. Enquanto prévia do mês passado ofereceu um vislumbre, hoje revela todo o poder desta arquitetura mobile-first. Gemma 3n foi projetado para a comunidade de desenvolvedores que ajudou a moldar o Gemma. É compatível com suas ferramentas favoritas, incluindo Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX e muitas outras, permitindo que você ajuste e implante facilmente seus aplicativos específicos no dispositivo. Esta postagem é o mergulho profundo do desenvolvedor: exploraremos algumas das inovações por trás do Gemma 3n, compartilharemos novos resultados de benchmark e mostraremos como começar a construir hoje.
Gemma 3n representa um grande avanço para a IA no dispositivo, trazendo capacidades multimodais poderosas para dispositivos de ponta com desempenho anteriormente visto apenas nos modelos de fronteira baseados em nuvem do ano passado.
Alcançar esse salto no desempenho do dispositivo exigiu repensar o modelo desde o início. A base é a arquitetura móvel exclusiva do Gemma 3n, e tudo começa com o MatFormer.
No centro de Gemma 3n está o Formas de comida (🪆Transformador Matryoshka) arquiteturaum novo transformador aninhado construído para inferência elástica. Pense nisso como uma boneca Matryoshka: um modelo maior contém versões menores e totalmente funcionais de si mesmo. Esta abordagem amplia o conceito de Aprendizagem de Representação Matryoshka desde apenas incorporações até todos os componentes do transformador.
Durante o treinamento MatFormer do modelo de parâmetro efetivo 4B (E4B), um submodelo de parâmetro efetivo 2B (E2B) é otimizado simultaneamente dentro dele, conforme mostrado na figura acima. Isso fornece aos desenvolvedores dois recursos e casos de uso poderosos hoje:
1: Modelos pré-extraídos: Você pode baixar e usar diretamente o modelo E4B principal para obter os recursos mais altos ou o submodelo E2B independente que já extraímos para você, oferecendo inferência até 2x mais rápida.
2: Tamanhos personalizados com Mix-n-Match: Para um controle mais granular adaptado a restrições específicas de hardware, você pode criar uma gama de modelos de tamanho personalizado entre E2B e E4B usando um método que chamamos de Mix-n-Match. Essa técnica permite fatiar com precisão os parâmetros do modelo E4B, principalmente ajustando a dimensão oculta da rede feed forward por camada (de 8192 a 16384) e ignorando seletivamente algumas camadas. Estamos liberando o Laboratório FoodFormeruma ferramenta que mostra como recuperar esses modelos ideais, que foram identificados pela avaliação de várias configurações em benchmarks como MMLU.
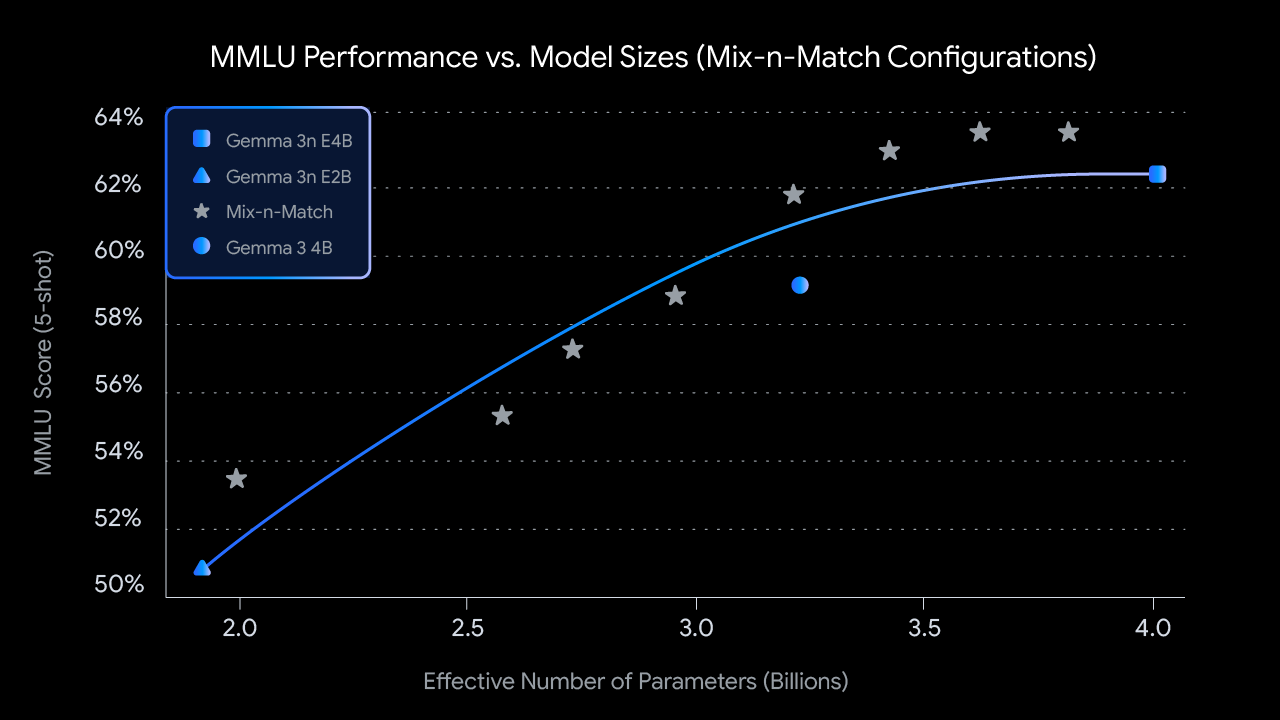
Pontuações MMLU para os pontos de verificação Gemma 3n pré-treinados em diferentes tamanhos de modelo (usando Mix-n-Match)
Olhando para o futuro, a arquitetura MatFormer também abre caminho para execução elástica. Embora não faça parte das implementações lançadas hoje, esse recurso permite que um único modelo E4B implantado alterne dinamicamente entre os caminhos de inferência E4B e E2B em tempo real, permitindo a otimização em tempo real do desempenho e do uso de memória com base na tarefa atual e na carga do dispositivo.
Os modelos Gemma 3n incorporam Incorporações por camada (PLE). Esta inovação é adaptada para implantação no dispositivo, pois melhora drasticamente a qualidade do modelo sem aumentar o consumo de memória de alta velocidade necessária no acelerador do seu dispositivo (GPU/TPU).
Embora os modelos Gemma 3n E2B e E4B tenham uma contagem total de parâmetros de 5B e 8B respectivamente, o PLE permite que uma parte significativa desses parâmetros (os embeddings associados a cada camada) seja carregada e computada de forma eficiente na CPU. Isso significa que apenas os pesos principais do transformador (aproximadamente 2B para E2B e 4B para E4B) precisam ficar na memória do acelerador (VRAM), normalmente mais restrita.

Com incorporações por camada, você pode usar o Gemma 3n E2B tendo apenas cerca de 2B de parâmetros carregados em seu acelerador.
O processamento de entradas longas, como sequências derivadas de fluxos de áudio e vídeo, é essencial para muitas aplicações multimodais avançadas no dispositivo. Gemma 3n apresenta o compartilhamento de cache KV, um recurso projetado para acelerar significativamente o tempo até o primeiro token para aplicativos de resposta de streaming.
O compartilhamento de cache KV otimiza como o modelo lida com o estágio inicial de processamento de entrada (geralmente chamado de fase de “pré-preenchimento”). As chaves e os valores da camada intermediária da atenção local e global são compartilhados diretamente com todas as camadas superiores, proporcionando uma melhoria notável de 2x no desempenho do pré-preenchimento em comparação com o Gemma 3 4B. Isso significa que o modelo pode ingerir e compreender sequências de prompt longas com muito mais rapidez do que antes.
Gemma 3n usa um codificador de áudio avançado baseado no Modelo de Fala Universal (USM). O codificador gera um token para cada 160 ms de áudio (cerca de 6 tokens por segundo), que são então integrados como entrada no modelo de linguagem, fornecendo uma representação granular do contexto sonoro.
Esse recurso de áudio integrado desbloqueia recursos importantes para desenvolvimento no dispositivo, incluindo:
Observamos resultados AST particularmente fortes para tradução entre inglês e espanhol, francês, italiano e português, oferecendo grande potencial para desenvolvedores que visam aplicações nesses idiomas. Para tarefas como tradução de fala, aproveitar a solicitação da cadeia de pensamento pode melhorar significativamente os resultados. Aqui está um exemplo:
user
Transcribe the following speech segment in Spanish, then translate it into English:
model Texto simples
No momento do lançamento, o codificador Gemma 3n é implementado para processar clipes de áudio de até 30 segundos. No entanto, esta não é uma limitação fundamental. O codificador de áudio subjacente é um codificador de streaming, capaz de processar áudios arbitrariamente longos com treinamento adicional de áudio de formato longo. Implementações de acompanhamento desbloquearão aplicativos de streaming longos e de baixa latência.
Juntamente com seus recursos de áudio integrados, o Gemma 3n apresenta um novo e altamente eficiente codificador de visão, MobileNet-V5-300Moferecendo desempenho de última geração para tarefas multimodais em dispositivos de ponta.
Projetado para flexibilidade e potência em hardware restrito, o MobileNet-V5 oferece aos desenvolvedores:
Este nível de desempenho é alcançado com múltiplas inovações arquitetônicas, incluindo:
Beneficiando-se de novos projetos arquitetônicos e técnicas avançadas de destilação, o MobileNet-V5-300M supera substancialmente o SoViT básico no Gemma 3 (treinado com SigLip, sem destilação). Em um Google Pixel Edge TPU, ele oferece uma aceleração de 13x com quantização (6,5x sem), requer 46% menos parâmetros e tem um consumo de memória 4x menorao mesmo tempo que fornece precisão significativamente maior em tarefas de linguagem visual
Estamos entusiasmados em compartilhar mais sobre o trabalho por trás deste modelo. Fique atento ao nosso próximo relatório técnico MobileNet-V5, que se aprofundará na arquitetura do modelo, estratégias de escalonamento de dados e técnicas avançadas de destilação.
Tornar o Gemma 3n acessível desde o primeiro dia tem sido uma prioridade. Temos orgulho de fazer parceria com muitos desenvolvedores de código aberto incríveis para garantir amplo suporte a ferramentas e plataformas populares, incluindo contribuições das equipes por trás da AMD, Axolotl, DockerAbraçando Rosto, llama.cpp, LMStudio, MLX, NVIDIAOllama, RedHat, SGLang, Unsloth e vLLM.
Mas este ecossistema é apenas o começo. O verdadeiro poder desta tecnologia está no que você construirá com ela. É por isso que estamos lançando o Desafio de Impacto Gemma 3n. Sua missão: usar os recursos exclusivos no dispositivo, off-line e multimodais do Gemma 3n para construir um produto para um mundo melhor. Com US$ 150.000 em prêmios, estamos procurando uma história em vídeo atraente e uma demonstração com fator “uau” que mostre o impacto no mundo real. Junte-se ao desafio e ajudar a construir um futuro melhor.
Pronto para explorar o potencial do Gemma 3n hoje? Veja como: