
Como profissionais de marketing, adoramos um ótimo funil. Ele fornece clareza sobre como nossas estratégias estão funcionando. Temos taxas de conversão e podemos acompanhar a jornada do cliente desde a descoberta até a conversão. Mas no mundo de hoje que prioriza a IA, nosso funil escureceu.
Ainda não podemos completamente medir a visibilidade em experiências de IA como ChatGPT ou Perplexity. Embora as ferramentas emergentes ofereçam insights parciais, seus dados não são abrangentes nem consistentemente confiáveis. As métricas tradicionais, como impressões e cliques, ainda não contam toda a história nesses espaços, deixando os profissionais de marketing diante de um novo tipo de lacuna de medição.
Para ajudar a esclarecer, vamos ver o que sabemos e o que não sabemos sobre como medir o valor dos dados estruturados (também conhecidos como marcação de esquema). Ao compreender ambos os lados, podemos concentrar-nos no que é mensurável e controlável hoje e onde estão as oportunidades à medida que a IA muda a forma como os clientes descobrem e interagem com as nossas marcas.
A IA criou uma fome por métricas. Os profissionais de marketing, desesperados para quantificar o que está acontecendo no topo do funil, estão recorrendo a uma onda de novas ferramentas. Muitas dessas plataformas estão criando novas medidas, como “autoridade de marca em plataformas de IA”, que não são baseadas em dados representativos.
Por exemplo, algumas ferramentas estão tentando medir “solicitações de IA” tratando frases curtas de palavras-chave como se fossem equivalentes a consultas de consumidores no ChatGPT ou Perplexity. Mas esta abordagem é enganosa. Os consumidores estão escrevendo avisos mais longos e ricos em contexto que vão muito além do que as métricas baseadas em palavras-chave sugerem. Esses prompts são matizados, coloquiais e altamente personalizados – nada como as consultas tradicionais de cauda longa.
Essas métricas sintéticas oferecem falso conforto. Eles desviam a atenção do que é realmente mensurável e controlável. O fato é que ChatGPT, Perplexity e até mesmo as visões gerais de IA do Google não estão nos fornecendo dados de visibilidade claros e abrangentes.
Então, o que podemos medir que realmente impacta a visibilidade? Dados estruturados.
Antes de mergulhar nas métricas, vale a pena definir “visibilidade de pesquisa de IA”. No SEO tradicional, visibilidade significava aparecer na primeira página dos resultados de pesquisa ou ganhar cliques. Num mundo orientado pela IA, visibilidade significa ser compreendido, confiável e referenciado tanto pelos motores de busca como pelos sistemas de IA. Os dados estruturados desempenham um papel nesta evolução. Ajuda a definir, conectar e esclarecer as entidades digitais da sua marca para que os mecanismos de pesquisa e os sistemas de IA possam entendê-las.
Vamos falar sobre o que é conhecido e mensurável hoje em relação aos dados estruturados.
A partir dos dados de nossa análise trimestral de negócios, vemos que, ao implementar dados estruturados em uma página, o conteúdo se qualifica para um resultado aprimorado e as marcas empresariais observam consistentemente um aumento nas taxas de cliques. Atualmente, o Google oferece suporte a mais de 30 tipos de resultados aprimoradosque continuam aparecendo na pesquisa orgânica.
Por exemplo, a partir de nossos dados internos, no terceiro trimestre de 2025, uma marca empresarial na indústria de eletrodomésticos viu as taxas de cliques nas páginas de produtos aumentarem em 300% quando uma pesquisa aprimorada foi concedida. Os resultados aprimorados continuam a fornecer ganhos de visibilidade e conversão da pesquisa orgânica.
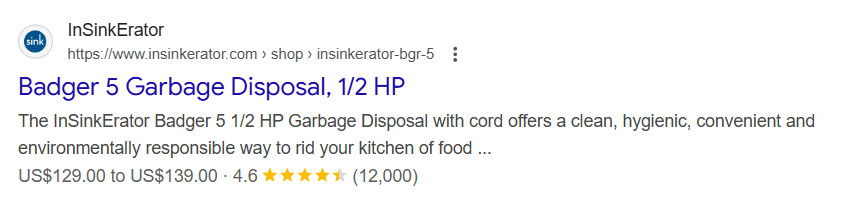 Exemplo de pesquisa aprimorada de produto na página de resultados do mecanismo de pesquisa do Google (captura de tela do autor, novembro de 2025)
Exemplo de pesquisa aprimorada de produto na página de resultados do mecanismo de pesquisa do Google (captura de tela do autor, novembro de 2025)É importante distinguir entre marcação de esquema básica e marcação de esquema robusta com vinculação de entidades que resulta em um gráfico de conhecimento. A marcação de esquema descreve o que está em uma página. A vinculação de entidades conecta essas coisas a outras entidades bem definidas em seu site e na web, criando relacionamentos que definem significado e contexto.
Uma entidade é uma coisa ou conceito único e distinguível, como uma pessoa, produto ou serviço. A vinculação de entidades define como essas entidades se relacionam entre si, seja por meio de fontes externas autorizadas, como o Wikidata e o gráfico de conhecimento do Google ou seu próprio gráfico de conhecimento de conteúdo interno.
Por exemplo, imagine uma página sobre um médico. A marcação do esquema descreveria o médico. Robusto, semântico a marcação também se conectaria ao Wikidata e ao gráfico de conhecimento do Google para definir sua especialidade, ao mesmo tempo em que se vincularia ao hospital e aos serviços médicos que eles fornecem.
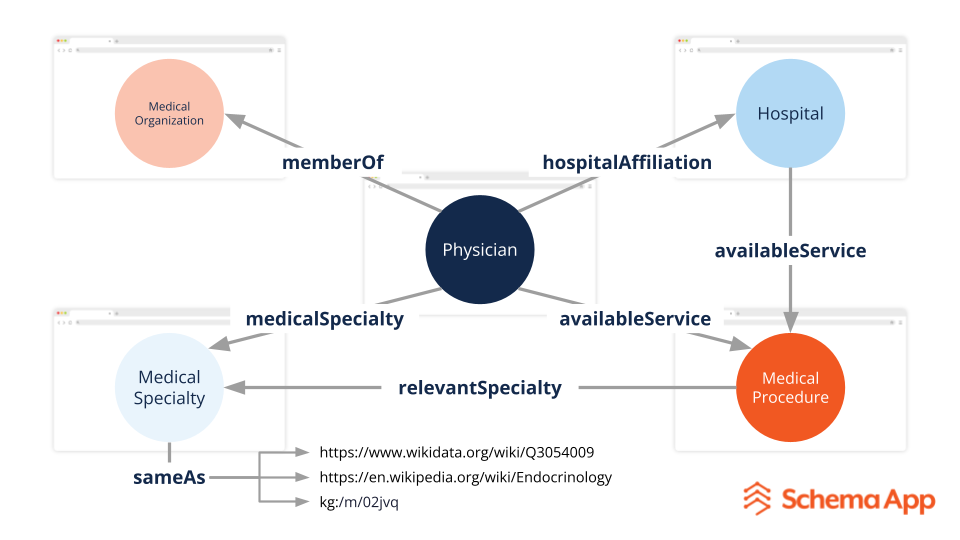 Imagem do autor, novembro de 2025
Imagem do autor, novembro de 2025As métricas tradicionais de SEO ainda não podem medir diretamente as experiências de IA, mas algumas plataformas podem identificar alguns casos em que uma marca é mencionada em um resultado de Visão Geral de IA (AIO).
A pesquisa de um relatório BrightEdge descobriu que a adoção de práticas de SEO baseadas em entidades oferece maior visibilidade da IA. O relatório observou:
“A IA prioriza o conteúdo de entidades conhecidas e confiáveis. Pare de otimizar para palavras-chave fragmentadas e comece a construir uma autoridade abrangente sobre o tópico. Nossos dados mostram que o conteúdo oficial tem três vezes mais probabilidade de ser citado nas respostas da IA do que páginas com foco restrito.”
Embora possamos medir o impacto das entidades na marcação de esquema por meio de métricas de SEO existentes, ainda não temos visibilidade direta de como esses elementos influenciam o desempenho do modelo de linguagem grande (LLM).
A visibilidade começa com a compreensão – e a compreensão começa com dados estruturados.
As evidências disso estão crescendo. Na postagem do blog da Microsoft de 8 de outubro de 2025, “Otimizando seu conteúdo para inclusão em respostas de pesquisa de IA (Microsoft Advertising”, Krishna Madhavengerente principal de produto do Microsoft Bing, escreveu:
“Para os profissionais de marketing, o desafio é garantir que seu conteúdo seja fácil de entender e estruturado de uma forma que os sistemas de IA possam usar.”
Ele acrescentou:
“Esquema é um tipo de código que ajuda os mecanismos de pesquisa e sistemas de IA a entender o seu conteúdo.”
Da mesma forma, o Google artigo“Principais maneiras de garantir que seu conteúdo tenha um bom desempenho nas experiências de IA do Google na Pesquisa”, reforça que “dados estruturados é útil para compartilhar informações sobre o seu conteúdo de uma forma legível por máquina.”
Por que o Google e a Microsoft estão enfatizando os dados estruturados? Um dos motivos pode ser o custo e a eficiência. Os dados estruturados ajudam a construir gráficos de conhecimento, que servem como base para uma IA mais precisa, explicável e confiável. A pesquisa mostrou que os gráficos de conhecimento podem reduzir as alucinações e melhorar o desempenho em LLMs:
Embora a marcação de esquema em si normalmente não seja ingerida diretamente para treinar LLMs, a fase de recuperação em sistemas de geração aumentada de recuperação (RAG) desempenha um papel crucial na forma como os LLMs respondem às consultas. Em trabalhos recentes, GraphRAG da Microsoft O sistema gera um gráfico de conhecimento (por meio de extração de entidade e relação) a partir de dados textuais e aproveita esse gráfico em seu pipeline de recuperação. Em seus experimentos, o GraphRAG geralmente supera uma abordagem RAG básica, especialmente para tarefas que exigem raciocínio multi-hop ou aterramento em entidades diferentes.
Isto ajuda a explicar porque é que empresas como a Google e a Microsoft estão a incentivar as marcas empresariais a investir em dados estruturados – é o tecido conjuntivo que ajuda os sistemas de IA a recuperar informações contextuais e precisas.
Há uma distinção importante entre otimizar uma única página para SEO e construir um gráfico de conhecimento que conecte todo o conteúdo da sua empresa. Em um recente entrevista com Robby Stein, vice-presidente de produto do Google, observou-se que as consultas de IA podem envolver dezenas de subconsultas nos bastidores (conhecidas como fan-out de consulta). Isto sugere um nível de complexidade que exige uma abordagem mais holística.
Para ter sucesso neste ambiente, as marcas devem ir além da otimização de páginas e, em vez disso, construir gráficos de conhecimento, ou melhor, uma camada de dados que represente todo o contexto do seu negócio.
O que é realmente interessante é que a visão para a web semântica está aqui. Como Tim Berners-Lee, Ora Lassila e James Hendler escreveram em “A Web Semântica” (Scientific American, 2001):
“A Web Semântica permitirá que as máquinas compreendam documentos e dados semânticos e permitirá que agentes de software percorram página a página para executar tarefas sofisticadas para os usuários.”
Estamos vendo isso acontecer hoje, com transações e consultas acontecendo diretamente em sistemas de IA como o ChatGPT. A Microsoft já está se preparando para o próximo estágio, muitas vezes chamado de “web agente”. Em novembro de 2024, RV Guha – criador de Schema.org e agora na Microsoft – anunciou um projeto aberto chamado NLWeb. O objetivo do NLWeb é ser “a maneira mais rápida e fácil de transformar efetivamente seu site em um aplicativo de IA, permitindo que os usuários consultem o conteúdo do site usando diretamente linguagem natural, assim como com um assistente de IA ou Copilot”.
Em uma conversa recente que tive com Guha, ele compartilhou que a visão da NLWeb é ser o ponto final para os agentes interagirem com os sites. NLWeb usará dados estruturados para fazer isso:
“NLWeb aproveita formatos semiestruturados como Schema.org… para criar interfaces de linguagem natural utilizáveis por humanos e agentes de IA.”
Assim como não temos métricas reais para medir o desempenho da marca no ChatGPT e no Perplexity, também não temos métricas completas para o papel da marcação de esquema na visibilidade da IA. Mas temos sinais claros e consistentes do Google e da Microsoft de que suas experiências de IA usam, em parte, dados estruturados para compreender o conteúdo.
O futuro do marketing pertence às marcas que são compreendidas e confiáveis pelas máquinas. Os dados estruturados são um fator para que isso aconteça.
Mais recursos:
Imagem em destaque: Roman Samborskyi/Shutterstock



